
【特集】OpenAIとMetaの水面下の衝突|Scale AIを巡る“データ供給戦争”実態解析
要約
- MetaがScale AIに約143〜148億ドル出資、CEOのAlexandr Wangを抱え込み、「スーパーインテリジェンス」部門を立ち上げ
- OpenAI(および他社)とのデータ供給契約が相次ぎ打ち切られ、Scale AIの立場に波乱
- 本件は AI開発の新たな戦場「データパイプ」 をめぐる超大国間ギア巡航戦争を象徴
なぜScale AI?Metaが取った巨大一手
- Metaは、Scale AIの49%を約143〜148億ドルで取得し、CEOのWang氏を自社スーパーインテリジェンス部門へ迎え入れ
- Scale AIは、画像や自然言語AI向けに高品質の人手ラベリングデータを提供する業界リーダーで、OpenAI、Google、Microsoftも主要顧客
- Metaがこの資源と人材を掌握することで、「モデル精度」より「データ質・供給網」が新たなAI戦略の鍵となる流れを作る狙い
OpenAIが契約打ち切りに動いた理由
- TechCrunchによれば、OpenAIはScale AIとの提携を進んで解消中。Bloombergも同方向を報道
- GBやMSも同様にScale AIから距離を置く動きを示し、業界全体でスーパー企業化への警戒感が高まっている
- Scale AIは「機密情報をMetaに渡さない」と声明を出したが、大手顧客の離脱は進んでおり、今後の供給体制に疑問が残る
「データインフラの掌握」がAIを制する構図に

- 高度AIはパイプライン型開発から、データ供給の質と供給網の安定性・独立性が競争力の分かれ目に
- Metaが同社ラベラー110万人にアクセスすることで、ラベリング効率・品質の急上昇が見込まれている
- 一方で多くの顧客は「中立な複数社契約モデル」を模索し始めており、Scale AIも代替先を確保し始めている
専門家の視点:「日本企業にとって何を意味するのか?」
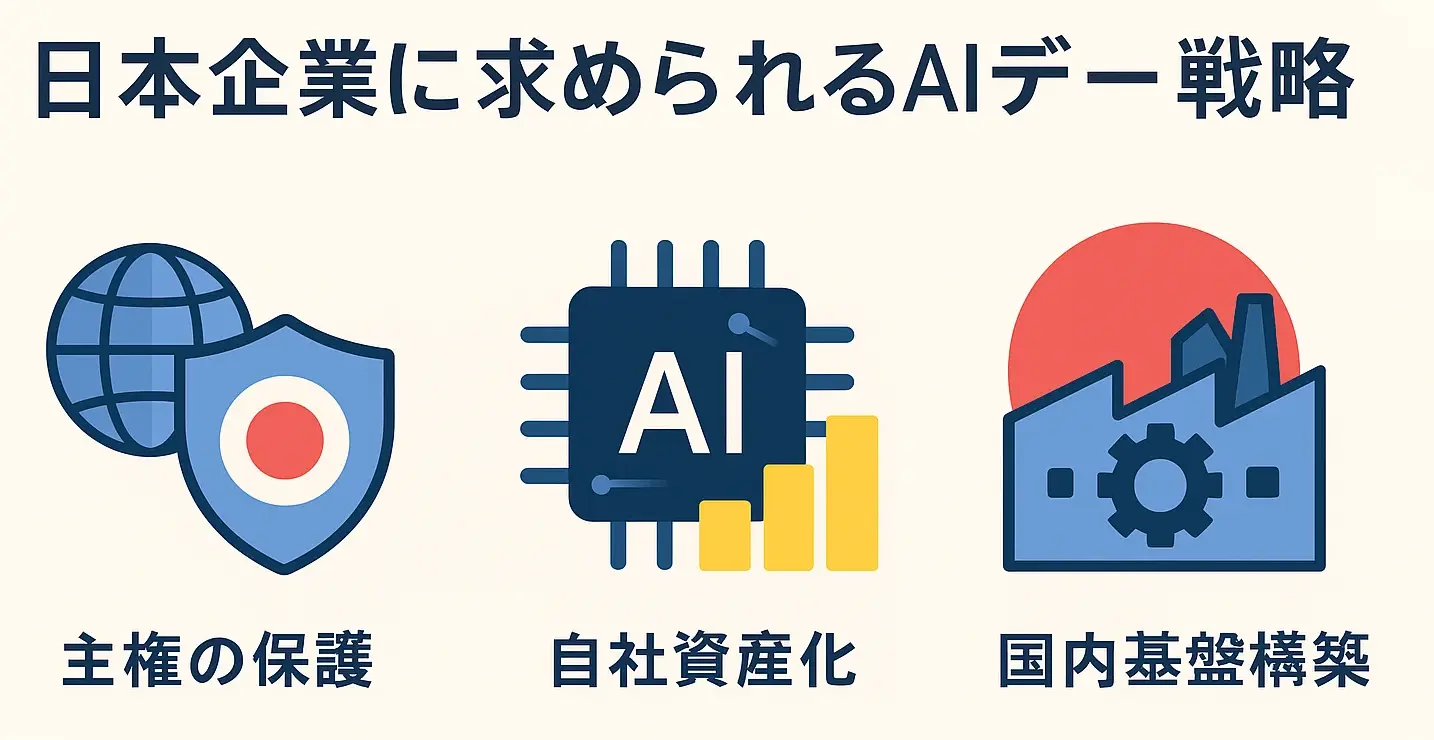
MetaによるScale AIへの巨額出資、そしてOpenAIの契約解消という一連の動きは、単なる企業間の取引ではありません。これは、「AI開発の競争軸がアルゴリズムから“データ供給インフラ”へと移りつつある」ことを象徴しています。
この構図は、特に大規模なデータ活用やAI基盤構築を担う日本の中堅〜大企業、さらには政策関係者にとって、3つの重要な示唆を含んでいます。
① データ供給の“地政学的リスク”が現実化
- データラベリングや供給網を一企業(今回で言えばMeta)に依存することは、突然の戦略転換・契約変更・情報漏洩リスクに直結します。
- 特に学習データの質・量がAI競争の優劣を決める現代では、データの主権性(Data Sovereignty)と供給の独立性をいかに保つかが死活的です。
② 自社の「学習データ資産」をどう確保・強化するか
- 今後、外部に頼るだけでなく、自社の業務・顧客・製造・医療・研究などの過程で生まれるファーストパーティーデータを、戦略的に整備・活用する動きが求められます。
- それには、データ収集・整備・ガバナンス・法的権利の明確化まで含めた、“データインフラ構築”の再設計が不可欠です。
③ 民間連携・公的支援による「国産ラベリング・基盤構築」の検討を
- 日本企業単体でのデータ主権確立には限界があります。
- 今こそ、国主導あるいは業界横断で、ラベリング・アノテーション・データ共有基盤を国内で整備する議論を加速すべき時です。
このような変化は、未来のAI社会における「支配構造」を形作る第一歩です。
いま、データを“買う”立場から、“持ち、守り、育てる”側へと日本全体がシフトできるかどうか──その分岐点に、私たちは立っています。
無料AIの知識を今すぐ入手!
最新AI情報をメールで受け取る
業務効率化やクリエイティブに役立つAIツールの最新情報とガイドを無料でメール配信!
今すぐ登録して始めよう。